Digit Recognition with Machine Learning 🦆🦆🦆🦆🦆
I implement a neural network for digit detection using the camera of the robot.
Contributors
Leen Alzebdeh, Tural Bakhtiyarli and Tianming Han
Objective
The main purpose of this exercise was to implement neural network to create a module for digit detection on AprilTags using the camera of our robots. We would also like to learn to run machine learning algorithm that handles the sensor input from robot from a remote laptop in real time, as this is a useful method to train/deploy an ML algorithm on a less powerful robot like the duckiebot.
Backward Propogation
Target = 1.0
Predicted (on pass 2) = 0.26
Learning rate = 0.05
Error Δ = 0.26 - 1 = - 0.74
[w5 w6]T = [0.17 0.17]T - 0.05(-0.74)$[0.92 0.56]T = [0.20404 0.19072]T ≈ [0.20 0.19]T
[w1 w2, w3 w4]T = [0.12 0.23, 0.13 0.10]T - 0.05(-0.74)[2 3]T[0.170.17] = [0.13258 0.24887 , 0.14258 0.11887]T ≈ [0.13 0.25, 0.14 0.12]T
To get the new prediction:
[2 3] [0.13 0.25, 0.14 0.12]T = [1.01 0.64] [0.20 0.19]T =[0.3236]
New error Δ = 0.3236 - 1 = - 0.6764
Summary:
[w5 w6] = [0.20 0.19]
| w1 w3 | 0.13 0.25 |
| w2 w4 | = | 0.14 0.12 |
Background
In the last exercise, we implemented autonomous lane following, where the Duckiebot can stay inside the lane while driving straight, and localize its position in the world using AprilTags. In this exercise we need a map in order to know the legal turns at an intersection, therefore we also included our AprilTag detection code from last exercise.
Neural Network Implementation
- Data augmentations used are:
-
- Randomly rotating the images
- Artificially making the pictures bigger and then cropping
- Normalizing the data
- Without the data augmentation, the accuracy of the model is decreased and it may face overfitting.
-
- The batch size in the code is 64. Higher batch size can lower the run time and reduce the noise in the data by averaging the gradient over a number of data points. On the other hand, lower batch size can prevent overfitting and be better for generalization as the model updates more frequently. The benefit of large batch size usually comes from its high degree of parallelism, where we can train the model over more samples without incurring much time cost via GPU or CPU vector operations, but changing batch sizes may require other hyper-parameters like learning rate etc. to be re-tuned.
- The activation function is the ReLU function, which is max(0,x), where x is the weighted sum of inputs to that neuron. This way, our model doesn’t have to deal with negative values, therefore leading to more accurate results and less error for training and validation. However, when we use linear activation function, we will have negative values to work with.Furthermore, ReLU prevents vanishing gradients as well.
- The optimization algorithm in the code is the Adam algorithm. Data optimization helps us to minimize the error between the predicted output and the actual output, which results in a more accurate model to work with. The optimization is usually done with a gradient descent algorithm or one of its variant.
- Adding dropout in the training causes some neurons not to be used in some stochastic manner. This results in redundancies in the use of neurons and therefore more robust neural networks.
Below shows the training result of ReLU vs. Linear Activation.
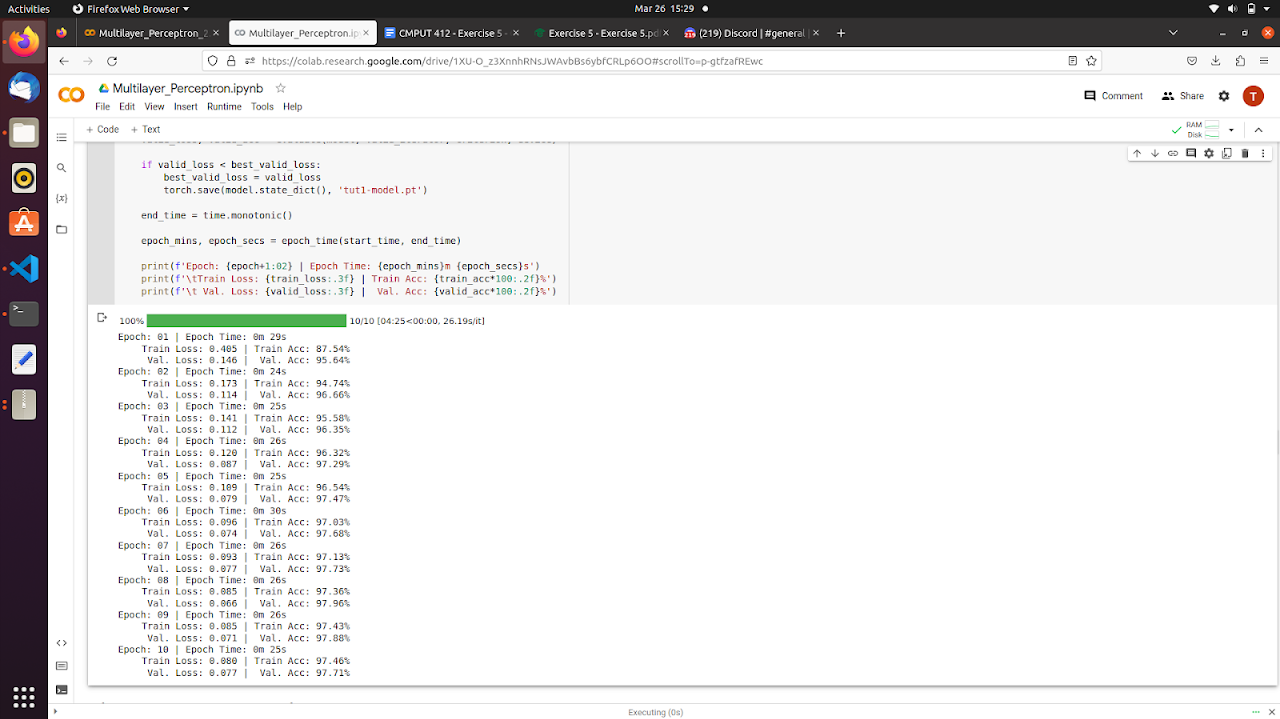
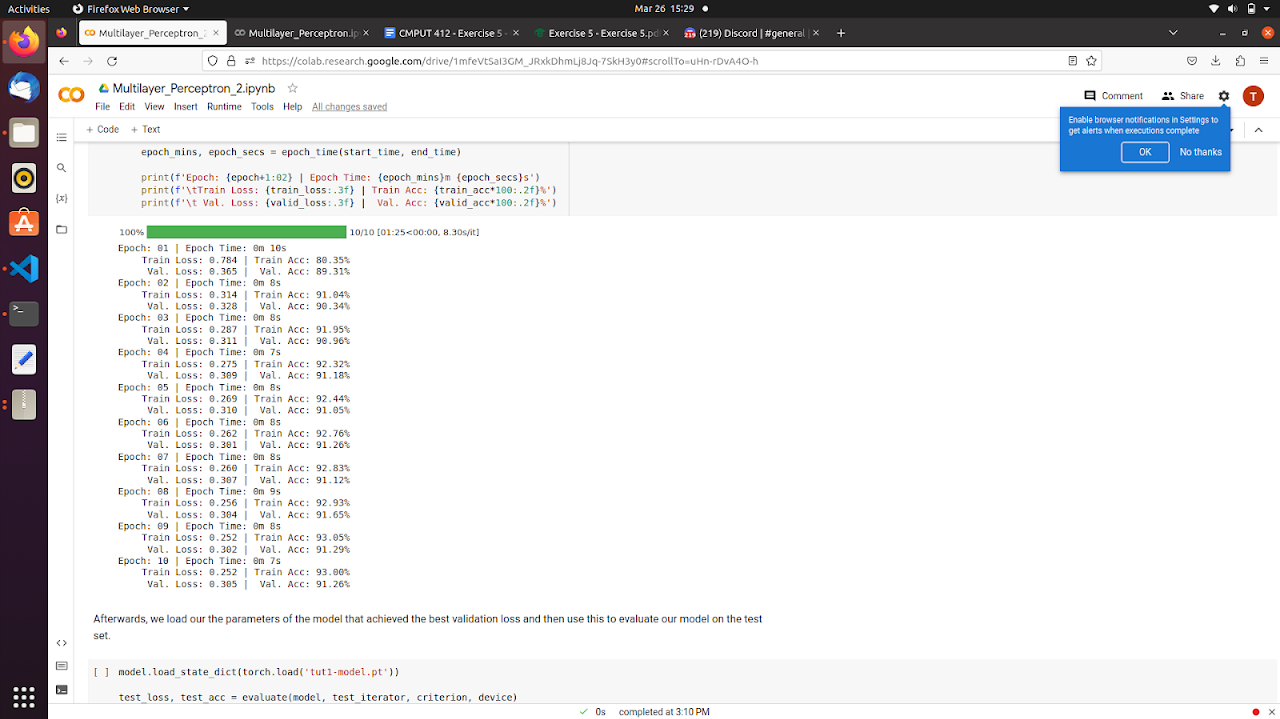
Methods
Cropping the Digit
The first challenge to recognize the digit is to find the place in the camera image where the digit is located. As the model we train is a classifier that takes in a square image of the digit, we look for a way to crop a bound box of the digit. To do this, we utilize the AprilTag detection: whenever a tag is detected, we use the center of the detected tag as a reference and look for the digit above it.
Given the digit’s rough position, we still need a way to find the digit while making sure not mistaking the darker environment as part of the black digit. The first approach we try is to use a black color mask to get the digit from the tag. However this easily mistakes the edges of the tag as part of the digit itself. We then try to use a blue mask and look for the contour surrounding the digit, and then get the inner contour as the digit image. However, this is still unreliable because the algorithm sometimes does not recognize the darker part of the blue sticker as part of the blue contour, which creates a ‘path’ from the digit and the edge of the sticker. The result is that there is no inner contour because the contour is disconnected.
After a while we realized we can combine the two methods: first use the blue contour to get a bound box for the digit accurately, then use black contour to carve out the digit. The result image still have some noisy lines and dots around the edges, but this can be dealt with by only taking the center ellipse of the 28 * 28 image and masking off the faraway part of the image. We tested the resulting algorithm, and found it running reliably as long as the image does not have too much motion blur.
Collecting Data
In order to train a model to run in real world, we need to first make sure we get a reasonable model that can run well in limited setting e.g. on a few camera images taken by the camera on the robot. This is done by recording a rosbag as the robot travels around and using OpenCV to display and select digit images manually. After manually selecting digits through, we collect 134 images of a handful of digits (retrospectively a oversight is that it does not include images for challenging digits like ‘1’ ) from a single rosbag and use them as a test set.
We use tensorflow as our tool to train an Multi-layer Perceptron(MLP) network on the MNIST dataset. First run of the model unfortunately fails on the 134 images test set despite having a 97% on the MNIST test set, having less than 50% accuracy. We then discovered that the accuracy is significantly improved if the training images in MNIST are artificially made thicker using cv2.dilate() function, and improved further when we add TMNIST into the training set: We discovered that MNIST is not a good choice for our task, and found a dataset of computer rendered digits which is the TMNIST (link below in reference section) dataset. After making these changes, the model is able to recognize ~110 of the 134 images correctly.
We then collected more digits by recording a rosbag to the cropped digit image topic and labelling them automatically by the AprilTag id they are on. The result are overall 1300+ of the ten digits. Training on these images yields a model that is able to correctly classify 128 of the 134 images. With some fine-tuning on those images following the Tensorflow tutorial on fine-tuning, the best result we are able to achieve is 132 image correctly classified out of 134 images.
Deploying the Model
We wrote a digit detection node on our laptop and run it through -R option. The node subscribes to the cropped digit image (labelled with a seq number to identify which tag they are from) and publishes a string “[seq] [detection_result]” back to the robot’s ml_node which detects AprilTags and keeps track of all the digits.
Running the node without lane following, we found that the model is able to identify the numbers on the tags most of the times, as demonstrated by the photos below.
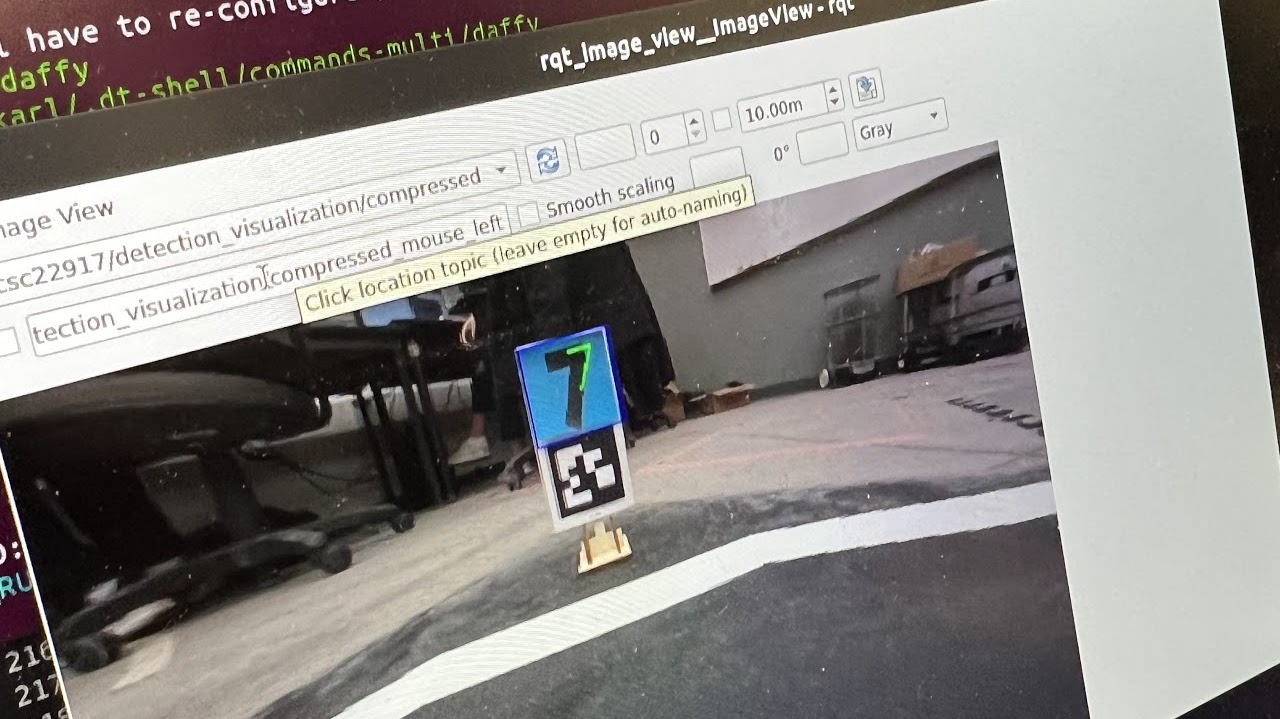
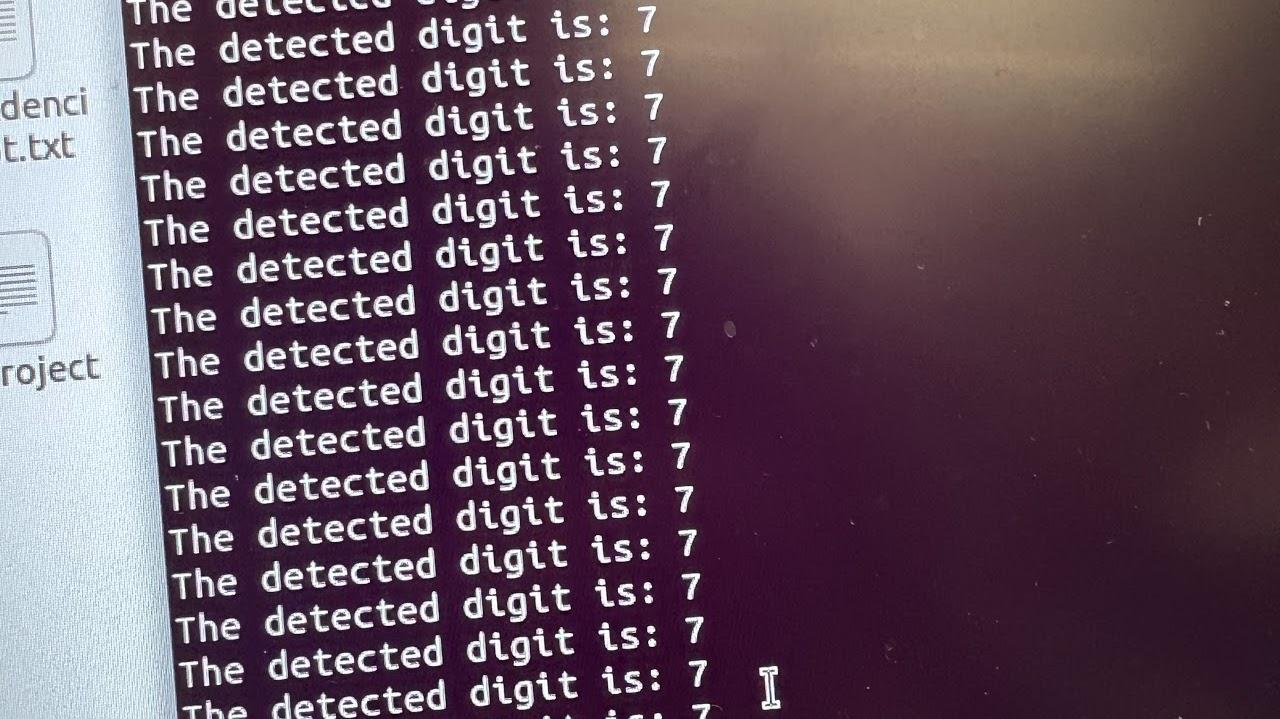
We then decide to run the lane following node together with the digit recognition, and we get the following video:
Results
After doing multiple test runs, we came into conclusion that the ML program worked well with most of the digits from most angles. Therefore, our program is mostly reliable under test circumstances. The accuracy of the program when tested with data from MNIST was 94%. The accuracy of the program when tested with the actual targets feels like around 85%.
Challenges that We Faced
One of the challenges we were facing was differentiating “1” and “7” from each other in the duckietown. As the top part of “7” in the Duckietown was tilted down, our program was sometimes confusing it with “1”. So, we had to take out “7” and place it back in a better position, which worked. Another issue that we faced was that the duckiebot was confusing the target digit with other digits, because it was still far away from the AprilTag and wasn’t close enough to make the right decision. However, we fixed this issue by calculating the distance between the AprilTag and the duckiebot. Then we used this information to limit the distance necessary for making correct decisions on the classification of the digits.
The two biggest unexpected challenge in this exercise were reliable turning at intersections and transformation broadcast. While we planned to use previous assignments and reference solutions for these parts at the start, it took a lot more time than we expected to integrate those code and debugging, and even in the final delivery these parts are still not as good as we’d like them to be (e.g. the odometry is not updating while we driving with deadreckoning).
Another unexpected challenge for us is the need to manually tune a model. Going into this assignment I had the impression that this assignment is focused on evaluating the existing MLP model (i.e. take the Google Colab script and run the result model on the robot) instead of training one from collected data. As a result we did not plan on spending time collecting data in the lab at the start.
References
MPL notebook https://eclass.srv.ualberta.ca/mod/resource/view.php?id=6964261
Tensorflow Documentation: https://www.tensorflow.org/api_docs/python/tf
Tensorflow Fine-tuning https://www.tensorflow.org/tutorials/images/transfer_learning#un-freeze_the_top_layers_of_the_model
AprilTag library: https://github.com/duckietown/lib-dt-AprilTags
Compressed Image ROS: http://wiki.ros.org/rospy_tutorials/Tutorials/WritingImagePublisherSubscriber
(Computer rendered) digit recognition with CNN: https://stackoverflow.com/questions/38389785/digit-recognition-on-cnn
Typeface MNIST dataset: https://www.kaggle.com/datasets/7a2a5621ee8c66c1aba046f9810a79aa27aafdbbe5d6a475b861d2ba8552d1fC